Unit of Work design pattern in Go
When working with a database, relational or not, and a large number of domain objects, one often risks of having to keep track of all the changes that need to be performed to ensure proper consistency. This can lead to a multitude of small read and write operations for the lifetime of a business transaction. This is not optimal.
Opening and closing database connections is costly and even when using a single connection and a database ‘Transaction’ can still lead to inconsistencies. Further more as a developer one might perform database operations from different code paths leading to even more tightly coupled code.
One way of avoiding this problem is to use an enterprise architectural pattern called Unit of Work. This design pattern is a behavioral pattern used to group business transactions that can impact the database. As Martin Fowler describes the Unit of Work as a design pattern that:
Maintains a list of objects affected by a business transaction and coordinates the writing out of changes and the resolution of concurrency problems.
I will not go into all the details about this design pattern, as better people than me have already done so, but I will look at how we can implement this pattern using Go. I will of course touch upon some ways of how the pattern can be used. For a full understanding of this design pattern I would suggest looking at the following book Patterns of Enterprise Application Architecture by Martin Fowler.
How
The way the pattern works is by simply keeping track of the different operations one must perform, creating new objects, modifying them and/or deleting them. Every single one of these operations will have to use the Unit of Work which will in turn handle the actual execution of such operations. When it comes time to commit the changes to the database the Unit of Work decides what to do and how.
This way of working has an added benefit, it adds an extra layer of indirection in ones code. By decoupling the ‘what’ needs to be done from the ‘how’ the operations are performed helps us keep our code more decoupled and less brittle in case of future changes.
We could start with an interface to help us sketch out the overall design of our Unit of Work
type UnitOfWork interface {
RegisterNew(newObject DomainObject)
RegisterDirty(modifiedObject DomainObject)
RegisterClean() //Optional function
RegisterDeleted(deletedObject DomainObject)
Commit()
}
Having an interface will also help us when we test our code, as an interface will allow us to mock the actual implementation and focus on code we want to test.
A more realistic implementation could look like so, where we have both an interface and an actual struct with relevant methods. Please note that the methods will have to perform some validation, but the important part is the actual book keeping of the domain object. This will allow us to handle the actual persistence later on.
package unitofwork
type (
Worker interface {
RegisterNew(newObject DomainObject)
RegisterDirty(modifiedObject DomainObject)
RegisterDeleted(deletedObject DomainObject)
Commit()
}
UnitOfWork struct {
database *Database
newObjects []DomainObject
modifiedObjects []DomainObject
deletedObjects []DomainObject
}
)
func New(database *Database) *UnitOfWork {
return &UnitOfWork{
database: database,
}
}
func (u *UnitOfWork) RegisterNew(newObject DomainObject) {
// Validate domain object
// ...
u.newObjects = append(u.newObjects, newObject)
}
func (u *UnitOfWork) RegisterDirty(modifiedObject DomainObject) {
// Validate domain object
// ...
u.modifiedObjects = append(u.modifiedObjects, modifiedObject)
}
func (u *UnitOfWork) RegisterDeleted(deletedObject DomainObject) {
// Validate domain object
// ...
u.deletedObjects = append(u.deletedObjects, deletedObject)
}
func (u UnitOfWork) Commit() {
// Handles the actual persistence logic
}
In the example above I have chosen to hold a reference to the Database via the Unit of Work but this might not always be the case. The way the Unit of Work interacts with the database depends on what design pattern one uses for Database interactions.
The next thing to look at is the way a developer will use the Unit of Work. Usually there are two main ways of implementing utilizing the design pattern, either with caller registration or with object registration
Caller Registration
With caller registration the responsibility lies with the caller of an object. When the caller updates the object it also has to remember to register the object with the Unit of Work and the corresponding operational change.
The advantage of this way is the flexibility gained by the caller which can more easily decide what operational change needs to be performed and registers the object in question when it deems it necessary.
The main drawback though is that any object that is not registered will not be written to the database when the Unit of Work commits the changes.
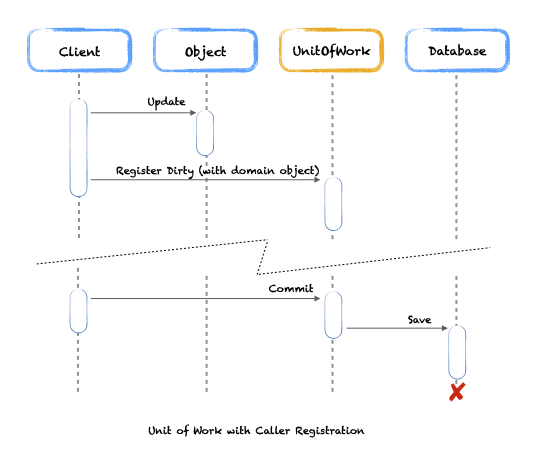
As you can see by the simple sequence diagram above the caller first interacts with the domain object and then calls the Unit of Work and registers the modified object.
Finally the caller will explicitly call Commit() to persist any changes to the database. As you can see from the diagram the Unit of Work calls directly the database layer, this is intentional. The example assumes that no database design pattern is being used as we want to keep the complexity to a minimum.
Object Registration
With object registration the responsibility lies with the object itself, and the most simple trick for this is to add the registration calls to the Unit of Work in the object’s modifier methods.
The advantage of this is that the caller does not even need to know about the presence of the Unit of Work for changes to be registered, it will however need to still call commit() when the changes need to be persisted.
The disadvantages are that the caller loses control over the object lifecycle and that the objects themselves need to somehow know about the Unit of Work. This second drawback can be easily overcome with a simple Inversion of Control (IoC) container or via constructor injection when the object is either read, and instantiated, from the database or created new.
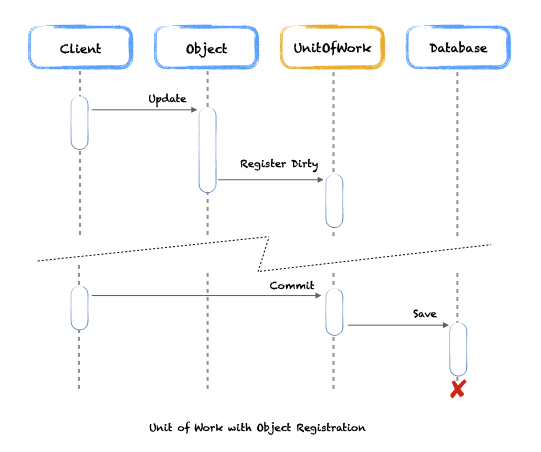
As you can see by this sequence diagram the caller only interacts with the domain objects and does not directly call the Unit of Work, it only does so when all the changes are performed on the domain objects and the changes need to be persisted to the database. It does so by calling Commit() but never registers any changes like in the previous example.
Again the Unit of Work calls directly the database layer, this is intentional. The example assumes that no database design pattern is being used as we want to keep the complexity to a minimum.
Committing
This is where the magic happens, and is the most interesting part of the design pattern, and yet one that depends on the chosen database implementation.
Unfortunately I cannot show in detail how the database persistence logic should be done, as this depends on how the application talks to the database. Several design pattern can be used here, be it a simple Data Access Layer, Data Mapper or Active Record the commit() method will have to perform different operations.
Having said that it is important to understand What the commit operation has to do, the how will depend on you.
First of all one will have to iterate over the different stored object references, the ones contained in newObjects,modifiedObjects and deletedObjects collections (Slices in Go parlance).
If you are using any of the above mentioned Database Design patterns, say for example the DataMapper, one can simply call the appropriate function on the mapper for the object one is iterating over. Here is a pseudo code example.
package unitofwork
import "mappers/registry"
//...
func (u UnitOfWork) Commit() {
for _, v := range modifiedObjects {
registry.GetMapper(reflect.TypeOf(v)).Update(v)
}
//...
}
One way I have personally handled this, while working with MongoDB, was to ensure that a minimal number of operation was performed. I chose to use a simple Data Access Layer and use Bulk Write to persist everything in one single operation. You can find the documentation for MongoDB here.
See Also
-
Alternative Command Design Pattern in Go
A more idiomatic command design pattern in Go and alternative way to implement this classic pattern -
Command design pattern in Go
A simple example of a design pattern in Go -
How to check if a key exists in a map in Go
How can you check if a key is present in a map in Go before accessing the map?